

|
Published: 29 April 2013
Disasters happen – but software shouldn’t be one of them
Imagine you’re a disaster manager and a large earthquake has just struck off the Australian coast. You know that part of the Australian coastline is about to be inundated by a tsunami but you need more information – and quickly. But what information do you need, and how do you get it?

|
|
A naval helicopter flies over the port of Sendai to deliver food to survivors of Japan’s devastating 9.0 magnitude earthquake and tsunami in 2011 – an oil refinery is burning in the background. CSIRO researchers have developed algorithms that can be applied to data collected by various federal and state government agencies to aid in the planning and prediction of natural hazard impacts. Credit: US Navy/Wikimedia Commons
|
The following might be on your need-to-know list: What size of tsunami will be created? What area will be flooded? How many people live in the exclusion zone? How many schools, hospitals and aged-care homes are inside? Which exit roads have bridges that are likely to withstand a flood of this scale?
With a team of experts you can find and collate this information, eventually. But you might have to contact several organisations that format their information in different ways.
Now imagine how much easier things would be if technology was available to pull information from multiple sources and feed them into the software of your choice.
You might want to use one piece of software for co-ordinating the response, then a second for recovery efforts and post-event analysis, and then a third for civil engineers designing new infrastructure.
We have some of these software tools already, but to enhance them we need to make it easier for them to utilise many sources of information in an assortment of formats.
The challenge is making the information ‘interoperable’– transforming it into formats that integrate with different software applications and modelling tools.
Managing disasters
In 2011, 322 natural disasters killed 30,773 people worldwide and inflicted US$366.1 billion worth of damage. Quite simply, the costs to human life and the economy make disaster management vital.
Modern disaster managers don’t just respond to events: they look at a spectrum of ‘Prevention, Preparedness, Response and Recovery’.
In Australia the national strategy for disasters focuses on building resilience, which is a community’s ability to withstand and recover from disaster events.
State and territory governments are largely responsible for responding to disasters. Volunteers and community organisations also contribute to disaster response and recovery efforts.
All hazards
Our research group in the Digital Productivity and Services Flagship is one of several at CSIRO involved in disaster research. CSIRO’s research into natural hazards ranges from flood modelling to bushfire research.
The focus in our group is how technology research can contribute to disaster management using an ‘all-hazards’ approach. We’re bringing together CSIRO’s technologies for disaster management, but we also work closely with other organisations.
Using an all-hazards approach is important because disasters are often related. A storm that causes damage with high winds might also lead to flooding; or a bushfire and heatwave could be linked. Disaster managers need to be able to pull together data from diverse sources to consider all hazards affecting an area.
Our researchers have developed algorithms and methodologies that, when applied to data collected by various federal and state government agencies, can aid in the planning and prediction phases of managing natural hazard impacts.
In practice, this might mean rainfall data (available from the Bureau of Meteorology) in conjunction with terrain information (Geoscience Australia) can be analysed computationally to predict flooding and tsunami risk areas.
Computational and mathematical methods already contribute to disaster management; and if we can bring more data and models together in an easy-to-use system, technology could contribute better.
To do that the data has to be compatible with many software clients.
Data compatibility
Dashboards and portals (websites that bring together information from diverse sources in a uniform way) let disaster managers make more insightful interpretations of data. Ideally they should take in a broad range of relevant details.
A fire portal could take in weather information, such as wind direction, but also information about fuel/vegetation types and topography (the lay of the land).
Such portals are already available, including one we developed that NSW Fire and Rescue is trialling. It brings together data from various federal and state agencies, including Geoscience Australia and the Bureau of Meteorology.
This prototype portal gives us an idea of what can be achieved with an all-hazards software client, and lets disaster managers test it and tell us what they need.
The limitation to the portal is that it can only take in certain types of data.
A software exchange layer
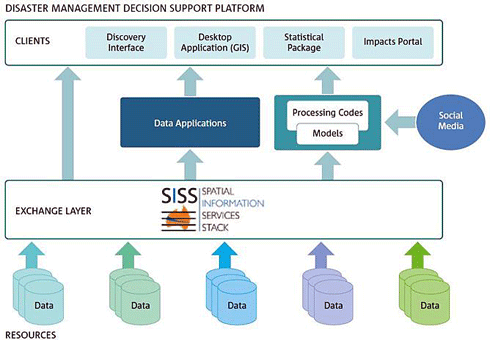
To help portals use more types of data, we’re creating a something known as the Disaster Management Decision Support Platform. The platform will fit in behind the scenes, converting data and feeding it to client software including a range of dashboards and portals.
Our platform is part of an ongoing strategy with a five-year vision to enable greater integration between data, models and computational codes that relate to natural disaster knowledge building.
The platform works acts as an ‘exchange layer’ (as per the diagram below) that will take information from data sources, transform it and feed it to the client software (which is the disaster management dashboard or portal).
|
|
The structure for CSIRO’s disaster management decision support platform. Credit: Ryan Fraser, CSIRO
|
The exchange layer has the job of making the data sources web accessible and converting them to formats that are interoperable between software clients.
It will also be able to integrate models, feeding data into them and then into client software. This means data can be processed in several ways before it reaches the client software.
Using the platform will allow client software designers to pull together more information in a single dashboard or portal without expending so much effort acquiring data and converting it between formats. That way more data sources can be used, making dashboards and portals better aids to decision-making.
So, to return to our original scenario, a large earthquake has just struck off the Australian coast. As the disaster manager, you have to make decisions, and quickly.
Now imagine an all-hazards portal that could use everything from government information to crowd-sourced data from mobile phones and social media, and all in real-time.
That would make your life easier, and more importantly would save countless other lives that may otherwise be lost or severely blighted.
This, in essence, is what we’re working towards.
Ryan Fraser is a software engineer for CSIRO Exploration and Mining’s Computational Geoscience for Predictive Discovery team and represents CSIRO in the Solid Earth and Environment Grid and the Australian Partnership for Advanced Computing (APAC) Grid projects. Arwen Cross is a CSIRO Communicator. This article was originally published at The Conversation.

